这几天做一个小项目,分给我的模块是对于BOKECC体系网站的抓取。
从来没有用过python,这次来尝一下鲜,感觉还行~
BOKECC就是一个视频网站的解决方案,我的任务很简单,就是给定一个网址,我来抓取对应页面上的数据内容。
整个系统采用分布式架构,我来负责做爬虫节点。

简单来说就是整个系统可分布式部署,每个节点接收来自控制者的远程调用,独立完成任务,并向上级汇报完成情况。
这里采用暴露WebService的方式来提供接口。
|
功能需求点
|
概述
|
|
输入
|
提供webservice接口供主控调用,异步启动爬虫任务。
|
|
输出
|
1. 在正常接收、启动任务后立即给主控返回接收成功。
2. 在完成任务/任务失败后调用主控提供的回调接口。
3. 抓取成功后,将抓取数据保存至数据库。
|
|
错误处理
|
抓取异常情况下,应该将错误原因汇报给主控,并记录日志。
|
|
并发性需求
|
模块支持多线程并发调用。
|
|
|
|
BOKECC体系网站有非常多个,通过进行实际情况调研,发现各个页面在数据上有所不同(但大同小异),为了省事,我决定只用一套代码来爬取所有对应站点。那就要求我们的代码具有通用性。
另外,客户端要实现0配置,爬取的结果写入数据库。(数据库配置参与也应该由控制者——WEB接口调用者来决定)。所以我们在节点上维护一个数据库连接池。
大致流程如下:
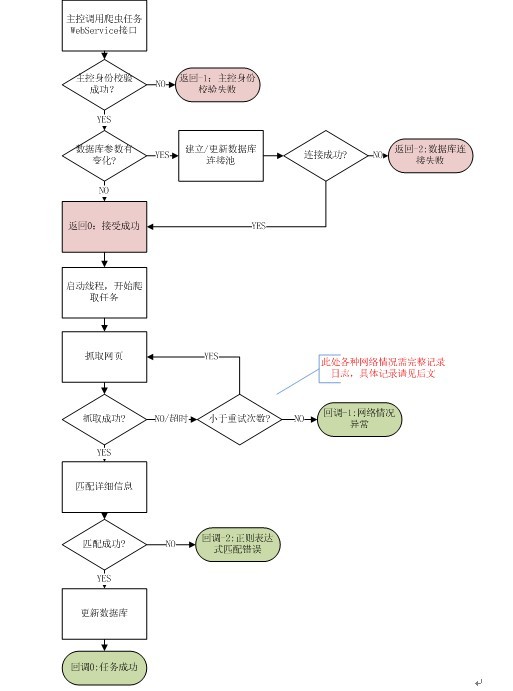
在实际编码过程中也没有严格遵守此流程,进行了相应的扩展,不过大体如上。
日志记录设计:
|
日志条目
|
级别
|
记录信息
|
|
WebService接口被调用
|
Info
|
调用方IP及各接口参数
|
|
主控身份校验失败
|
Warn
|
调用方IP
|
|
开始建立/更新数据库连接池
|
Info
|
数据库参数
|
|
数据库连接失败
|
Error,Notify
|
失败原因
|
|
数据库连接成功
|
Info
|
|
|
开始启动爬虫任务
|
Debug
|
|
|
开始抓取网页
|
Info
|
URL
|
|
一次网页抓取超时
|
Warn
|
当前重试次数
|
|
一次网页抓取异常
|
Warn
|
异常原因
|
|
重试范围内网页抓取失败
|
Error,Notify
|
|
|
网页抓取成功
|
Debug
|
|
|
开始内容匹配
|
Info
|
|
|
正则表达式匹配失败
|
Error,Notify
|
失败字段、失败原因
|
|
正则表达式匹配成功
|
Debug
|
|
|
开始更新数据库
|
Info
|
|
|
SQL操作
|
Debug
|
SQL语句
|
|
更新数据库完成
|
Debug
|
|
|
写数据库异常
|
Error,Notify
|
当前执行的SQL语句,异常原因
|
|
任务成功
|
Info
|
|
技术选型:
开发平台: windowsXP
部署平台: 跨平台
编程语言:python2.5
IDE+plug-in:MyEclipse 7.0 + pydev
具体使用的python技术:
|
功能
|
技术选型
|
|
网页抓取
|
urllib2
|
|
内容解析,正则表达
|
re
|
|
WebService
|
ZSI2.0
|
|
SOAP协议
|
SOAPpy(ZSI依赖)
|
|
XML
|
pyXML(ZSI依赖)
|
|
Web服务器
|
ZSI自带SOAP SERVER 或Apache
|
|
发布、部署
|
Windows平台:py2exe
|
下面一节将进入正式编码阶段。
分享到:





相关推荐
Python基于Django的实战项目源码——美多商城 Python基于Django的实战项目源码——美多商城 Python基于Django的实战项目源码——美多商城 Python基于Django的实战项目源码——美多商城 Python基于Django的...
Python的网页数据抓取,表格的制作,CSS文件的生成,字体的改变
python爬取网页视频(csdn)————程序
Python分布式网络抓取器是指使用Python编程语言实现的网络抓取工具,该工具可以将爬取任务分发给多台计算机或服务器进行并行处理。通过分布式的方式,可以有效地提高爬取效率和处理能力。 传统的单机爬虫在处理大...
python项目——Excel数据分析师.zip python项目——Excel数据分析师.zip python项目——Excel数据分析师.zip python项目——Excel数据分析师.zip python项目——Excel数据分析师.zip python项目——Excel数据分析师....
基于Python的分布式网络爬虫系统的设计与实现
Python爬虫技术的网页数据抓取与分析.pdf
基于python的分布式深度学习任务管理系统.zip基于python的分布式深度学习任务管理系统.zip基于python的分布式深度学习任务管理系统.zip基于python的分布式深度学习任务管理系统.zip基于python的分布式深度学习任务...
基于Python的分布式文件共享系统的实现.pdf
基于Python的分布式爬虫系统的设计与实现.pdf基于Python的分布式爬虫系统的设计与实现.pdf基于Python的分布式爬虫系统的设计与实现.pdf基于Python的分布式爬虫系统的设计与实现.pdf基于Python的分布式爬虫系统的设计...
基于Python的分布式系统实现无中心节点任务调度源码.zip基于Python的分布式系统实现无中心节点任务调度源码.zip基于Python的分布式系统实现无中心节点任务调度源码.zip基于Python的分布式系统实现无中心节点任务调度...
python 处理json数据(csdn)————程序
基于Python的分布式网络爬虫系统的设计与实现.pdf
python期末复习——python知识要点(csdn)————程序
DPark 是 Spark 的 Python 克隆,是一个Python实现的分布式计算框架,可以非常方便地实现大规模数据处理和迭代计算。 DPark 由豆瓣实现,目前豆瓣内部的绝大多数数据分析都使用DPark 完成。
外部python调用houdini python(csdn)————程序
python打印三角形(csdn)————程序
python+scrapy框架编写的淘宝数据抓取爬虫。输入要抓取商品的关键字,抓取相关数据
python定点数(csdn)————程序
python 进程池(csdn)————程序